Excel example 1 - extrapolation calculations
Roche
2023-05-02
Excel_example_ex1.RmdIntroduction
This vignette describes how to work with the included example excel templates that are compatible to the survival models estimated with flexsurvPlus. These examples are deliberately simple and are intended to illustrate calculations in excel rather than as a basis for a real economic model. In this example the basic calculations needed to extrapolate survival are illustrated.
Set up packages and data
Generate the data
To perform survival analyses, patient level data is required for the survival endpoints. In this example, we analyze progression-free survival (PFS). For more details on these steps please refer to the other vignettes.
# make reproducible
set.seed(1234)
# used later
(simulation_seed <- floor(runif(1, min = 1, max = 10^8)))
#> [1] 11370342
(bootstrap_seed <- floor(runif(1, min = 1, max = 10^8)))
#> [1] 62229940
# low number for speed of execution given illustrating concept
n_bootstrap <- 10
adtte <- sim_adtte(seed = simulation_seed)
head(adtte)
#> USUBJID ARMCD ARM PARAMCD PARAM AVAL AVALU
#> 1 1 A Reference Arm A PFS Progression Free Survival 108 DAYS
#> 2 2 A Reference Arm A PFS Progression Free Survival 150 DAYS
#> 3 3 A Reference Arm A PFS Progression Free Survival 372 DAYS
#> 4 4 A Reference Arm A PFS Progression Free Survival 73 DAYS
#> 5 5 A Reference Arm A PFS Progression Free Survival 137 DAYS
#> 6 6 A Reference Arm A PFS Progression Free Survival 103 DAYS
#> CNSR
#> 1 0
#> 2 0
#> 3 0
#> 4 0
#> 5 0
#> 6 0
# subset PFS data and rename
PFS_data <- adtte %>%
filter(PARAMCD == "PFS") %>%
transmute(USUBJID,
ARMCD,
PFS_days = AVAL,
PFS_event = 1 - CNSR
)Fitting the models
More information about each function can be used by running the code ?runPSM or viewing the other vignettes.
psm_PFS_all <- runPSM(
data = PFS_data,
time_var = "PFS_days",
event_var = "PFS_event",
model.type = c(
"Common shape",
"Independent shape",
"Separate"
),
distr = c(
"exp",
"weibull",
"gompertz",
"lnorm",
"llogis",
"gengamma",
"gamma",
"genf"
),
strata_var = "ARMCD",
int_name = "B",
ref_name = "A"
)Bootstrap the estimated parameters
As described in other vignettes we can use boot to
explore uncertainty.
Exporting to Excel
Once the values are calculated we can export to Excel. The following code prepares two tibbles that can be exported. One containing the main estimates. A second containing the bootstrap samples.
main_estimates <- psm_PFS_all$parameters_vector %>%
t() %>%
as.data.frame()
boot_estimates <- boot_psm_PFS_all$t %>%
as.data.frame()
colnames(main_estimates) <- colnames(boot_estimates) <- names(psm_PFS_all$parameters_vector)
# can preview these tables
main_estimates[, 1:5] %>%
pander::pandoc.table()
#>
#> ----------------------------------------------------------------
#> comshp.exp.rate.int comshp.exp.rate.ref comshp.exp.rate.TE
#> --------------------- --------------------- --------------------
#> 0.002711 0.005584 -0.7226
#> ----------------------------------------------------------------
#>
#> Table: Table continues below
#>
#>
#> -----------------------------------------------------
#> comshp.weibull.scale.int comshp.weibull.scale.ref
#> -------------------------- --------------------------
#> 370.9 193.4
#> -----------------------------------------------------
boot_estimates[1:3, 1:5] %>%
pander::pandoc.table()
#>
#> ----------------------------------------------------------------
#> comshp.exp.rate.int comshp.exp.rate.ref comshp.exp.rate.TE
#> --------------------- --------------------- --------------------
#> 0.002409 0.006054 -0.9214
#>
#> 0.002592 0.005716 -0.7907
#>
#> 0.002603 0.005959 -0.8283
#> ----------------------------------------------------------------
#>
#> Table: Table continues below
#>
#>
#> -----------------------------------------------------
#> comshp.weibull.scale.int comshp.weibull.scale.ref
#> -------------------------- --------------------------
#> 410.9 177
#>
#> 383.7 188.9
#>
#> 384.4 183.9
#> -----------------------------------------------------
# the following code is not run in the vignette but will export this file
# require(openxlsx)
# wb <- openxlsx::createWorkbook()
# openxlsx::addWorksheet(wb, sheetName = "Exported data")
# openxlsx::writeDataTable(wb, sheet = "Exported data", main_estimates, startRow = 2, startCol = 2)
# openxlsx::writeDataTable(wb, sheet = "Exported data", boot_estimates, startRow = 5, startCol = 2)
# openxlsx::createNamedRegion(wb, sheet = "Exported data",
# cols = 2:(2+length(main_estimates)), rows = 3, name = "Estimates")
# openxlsx::createNamedRegion(wb, sheet = "Exported data",
# cols = 2:(2+length(main_estimates)), rows = 6:(6-1+nrow(boot_estimates)), name = "Samples")
# openxlsx::saveWorkbook(wb, file = "export_data.xlsx", overwrite = TRUE)The Excel model
Included with the package is an example Excel file called
ex1_calculation.xlsx. This can be extracted using the below
code (not run). It can also be found in the github repository at https://github.com/Roche/flexsurvPlus/tree/main/inst/extdata
installed_file <- system.file("extdata/ex1_calculation.xlsx", package = "flexsurvPlus")
installed_file
#> [1] "/usr/local/lib/R/site-library/flexsurvPlus/extdata/ex1_calculation.xlsx"
# not run but will give you a local copy of the file
# file.copy(from = installed_file, to ="copy_of_ex1_calculation.xlsx")This illustrates how all the included survival models can be extrapolated in Excel.
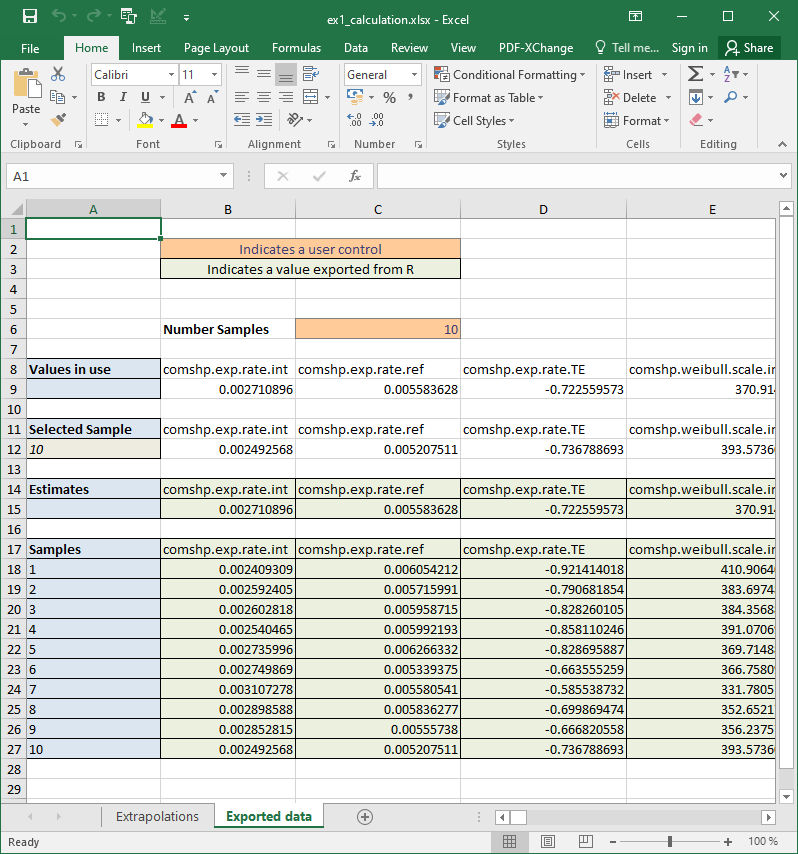
Extrapolations tab
This contains example calculations to extrapolate survival.
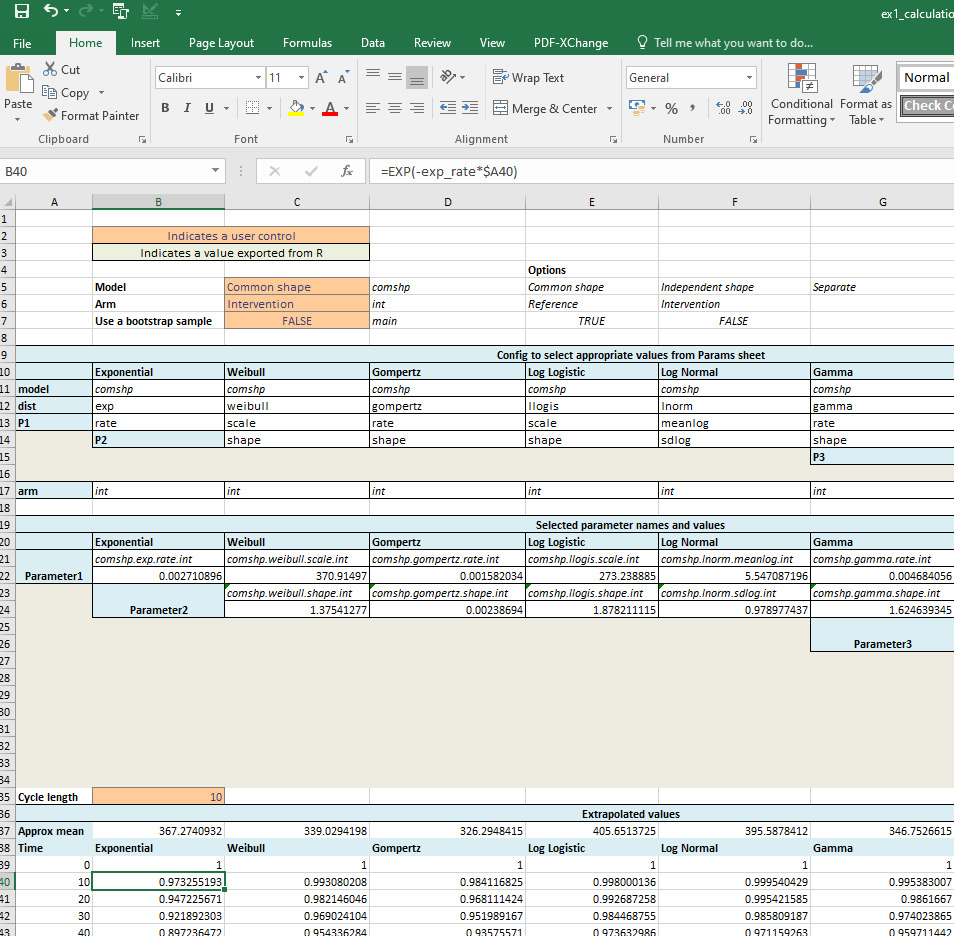
Extrapolations tab
We can compare the approximate estimates of mean survival with those calculated in R. As the excel model only goes until time t=2000 we can more directly compare to the estimates of restricted mean survival time (rmst) until this time.
means_est <- psm_PFS_all %>%
summaryPSM(type = c("mean", "rmst"), t = 2000)
# match to selected model in screenshot
means_est %>%
dplyr::filter(Model == "Common shape", Strata == "Intervention") %>%
tidyr::pivot_wider(
id_cols = c("Dist"),
names_from = c("type"),
values_from = "value"
) %>%
pander::pandoc.table()
#>
#> -----------------------------------
#> Dist mean rmst
#> ------------------- ------- -------
#> Exponential 368.9 367.3
#>
#> Weibull 339 339
#>
#> Gompertz 326.3 326.3
#>
#> Log Normal 414.2 395.6
#>
#> Log Logistic 459.4 405.7
#>
#> Generalized Gamma 338.8 338.8
#>
#> Gamma 346.8 346.8
#>
#> Generalized F 342.6 342.5
#> -----------------------------------