suppressPackageStartupMessages({
library(crmPack)
library(knitr)
library(kableExtra)
library(tidyr)
library(magrittr)
library(dplyr)
})Introducing tidy methods to crmPack
The latest release of crmPack introduces
broom-like tidy methods for all crmPack
classes. These methods convert the underlying S4 classes to (lists of)
tibbles. This should facilitate reporting of all aspects of
CRM trials as well as making it easier to integrate crmPack
with other packages such as ggplot2.
Basic approach
The following is the general approach we take to tidying
crmPack classes:
- All slots that are not functions are converted to
tibbles or a list oftibbles. - If the slot’s value is a
list, these rules are applied to each element of the list in turn. - If the slot’s value is scalar, the slot is converted to a 1x1
tibble. This will ease downstream operations such asrow_binding. - If the object being tidied contains multiple slots of (potentially)
different lengths, the result is a list of
tibbles. The list may be nested to multiple levels. (See, for example,LogisticLogNormal.) - The column names of the tidied
tibblecorrespond to the slot names of the parent object.- Exception: where the slot has name in the plural and contains a
vectororlist, the column name will be singular. See, for example,CohortSizePartsbelow.
- Exception: where the slot has name in the plural and contains a
- When the value of a slot has not been set, a zero-row
tibbleis returned. - When the value of a slot has scalar attributes, these attributes are
added as columns of the
tibble, whose name is the name of the attribute and whose value is the value of the attribute for every row of the tibble. Vector attributes can be added, by default, as a nested tibble. The nested tibble is 1 row x n column, with column names defined by the name of the attribute and values given by the value of the corresponding attribute. -
tbl_<className>is prepended to the class of the (list of) tidytibble(s).
Exceptions
- Where a vector slot (or series of vector slots) define a range ()for
example, the
intervalsslot in variousCohortSizeandIncrementsclasses, then the naming convention described above is not followed. Instead, columns namedminandmaxdefine the extent of the range.
Examples
CohortSizeConst is a trivial example and illustrates the
default approach for all classes.
CohortSizeConst(size = 3) %>% tidy()
#> # A tibble: 1 × 1
#> size
#> <int>
#> 1 3IncrementsRelative illustrate how ranges are
handled.
IncrementsRelative(
intervals = c(0, 20),
increments = c(1, 0.33)
) %>%
tidy()
#> # A tibble: 2 × 3
#> min max increment
#> <dbl> <dbl> <dbl>
#> 1 0 20 1
#> 2 20 Inf 0.33CohortSizeMax contains a slot whose value is a list.
cs_max <- maxSize(
CohortSizeConst(3),
CohortSizeDLT(intervals = 0:1, cohort_size = c(1, 3))
)
cs_max %>% tidy()
#> [[1]]
#> # A tibble: 1 × 1
#> size
#> <int>
#> 1 3
#>
#> [[2]]
#> # A tibble: 2 × 3
#> min max cohort_size
#> <dbl> <dbl> <int>
#> 1 0 1 1
#> 2 1 Inf 3
#>
#> attr(,"class")
#> [1] "tbl_CohortSizeMax" "tbl_CohortSizeMax" "list"The Samples class likely to the most useful when making
presentations not yet supported by crmPack directly.
options <- McmcOptions(
burnin = 100,
step = 1,
samples = 2000
)
emptydata <- Data(doseGrid = c(1, 3, 5, 10, 15, 20, 25, 40, 50, 80, 100))
model <- LogisticLogNormal(
mean = c(-0.85, 1),
cov =
matrix(c(1, -0.5, -0.5, 1),
nrow = 2
),
ref_dose = 56
)
samples <- mcmc(emptydata, model, options)
tidySamples <- samples %>% tidy()
tidySamples %>% head()
#> $data
#> # A tibble: 2,000 × 10
#> Iteration Chain alpha0 alpha1 nChains nParameters nIterations nBurnin nThin
#> <int> <int> <dbl> <dbl> <int> <int> <int> <int> <int>
#> 1 1 1 -1.81 9.09 1 1 2100 100 1
#> 2 2 1 -1.06 18.5 1 1 2100 100 1
#> 3 3 1 -2.27 15.5 1 1 2100 100 1
#> 4 4 1 -1.03 4.85 1 1 2100 100 1
#> 5 5 1 -1.32 61.2 1 1 2100 100 1
#> 6 6 1 -1.09 2.76 1 1 2100 100 1
#> 7 7 1 -0.673 0.501 1 1 2100 100 1
#> 8 8 1 -2.02 5.94 1 1 2100 100 1
#> 9 9 1 -0.941 2.53 1 1 2100 100 1
#> 10 10 1 -1.60 13.9 1 1 2100 100 1
#> # ℹ 1,990 more rows
#> # ℹ 1 more variable: parallel <lgl>
#>
#> $options
#> # A tibble: 1 × 5
#> iterations burnin step rng_kind rng_seed
#> <int> <int> <int> <chr> <int>
#> 1 2100 100 1 NA NAUsing tidy crmPack data
Tidy crmPack data can be easily reported using
knitr or similar packages in the obvious way.
Cohort size
The cohort size for this trial is determined by the dose to be used in the current cohort according to the rules described in the table below:
CohortSizeRange(
intervals = c(0, 50, 300),
cohort_size = c(1, 3, 5)
) %>%
tidy() %>%
kable(
col.names = c("Min", "Max", "Cohort size"),
caption = "Rules for selecting the cohort size"
) %>%
add_header_above(c("Dose" = 2, " " = 1))| Min | Max | Cohort size |
|---|---|---|
| 0 | 50 | 1 |
| 50 | 300 | 3 |
| 300 | Inf | 5 |
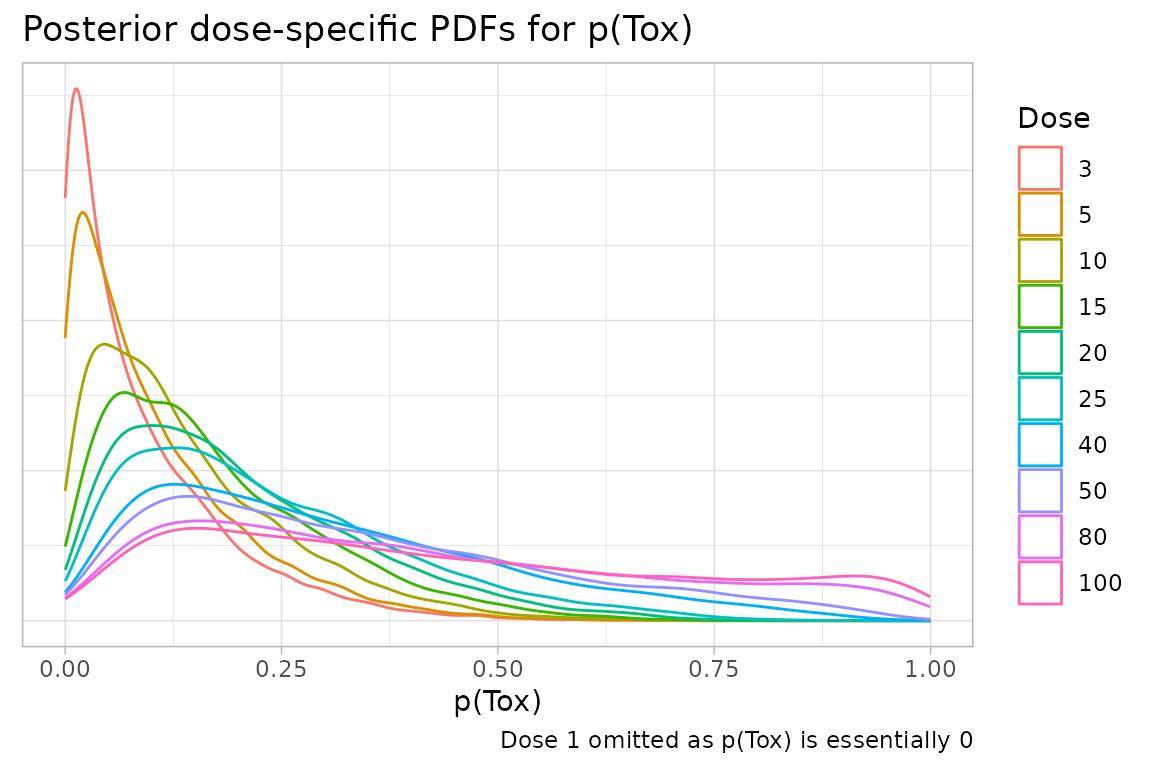
Or presentations not directly supported by crmPack can
be easily produced. Here, we create plots of the dose-specific PDFs for
prior probabilities of toxicity after the first DLT is observed in a
fictional trial.
options <- McmcOptions(
burnin = 5000,
step = 1,
samples = 40000
)
data <- Data(
doseGrid = c(1, 3, 5, 10, 15, 20, 25, 40, 50, 80, 100),
x = c(1, 3, 5, 10, 15, 15, 15),
y = c(0, 0, 0, 0, 0, 1, 0),
ID = 1L:7L,
cohort = as.integer(c(1:4, 5, 5, 5))
)
model <- LogisticLogNormal(
mean = c(-1, 0),
cov =
matrix(c(3, -0.1, -0.1, 4),
nrow = 2
),
ref_dose = 56
)
samples <- mcmc(data, model, options)
tidySamples <- samples %>% tidy()
# The magrittr pipe is necessary here
tidySamples$data %>%
expand(
nesting(!!!.[1:10]),
Dose = data@doseGrid[2:11]
) %>%
mutate(Prob = probFunction(model, alpha0 = alpha0, alpha1 = alpha1)(Dose)) %>%
ggplot() +
geom_density(aes(x = Prob, colour = as.factor(Dose)), adjust = 1.5) +
labs(
title = "Posterior dose-specific PDFs for p(Tox)",
caption = "Dose 1 omitted as p(Tox) is essentially 0",
x = "p(Tox)"
) +
scale_colour_discrete("Dose") +
theme_light() +
theme(
axis.ticks.y = element_blank(),
axis.text.y = element_blank(),
axis.title.y = element_blank()
)
Environment
sessionInfo()
#> R version 4.3.3 (2024-02-29)
#> Platform: x86_64-pc-linux-gnu (64-bit)
#> Running under: Ubuntu 22.04.4 LTS
#>
#> Matrix products: default
#> BLAS: /usr/lib/x86_64-linux-gnu/openblas-pthread/libblas.so.3
#> LAPACK: /usr/lib/x86_64-linux-gnu/openblas-pthread/libopenblasp-r0.3.20.so; LAPACK version 3.10.0
#>
#> locale:
#> [1] LC_CTYPE=en_US.UTF-8 LC_NUMERIC=C
#> [3] LC_TIME=en_US.UTF-8 LC_COLLATE=en_US.UTF-8
#> [5] LC_MONETARY=en_US.UTF-8 LC_MESSAGES=en_US.UTF-8
#> [7] LC_PAPER=en_US.UTF-8 LC_NAME=C
#> [9] LC_ADDRESS=C LC_TELEPHONE=C
#> [11] LC_MEASUREMENT=en_US.UTF-8 LC_IDENTIFICATION=C
#>
#> time zone: Etc/UTC
#> tzcode source: system (glibc)
#>
#> attached base packages:
#> [1] stats graphics grDevices utils datasets methods base
#>
#> other attached packages:
#> [1] dplyr_1.1.4 magrittr_2.0.3 tidyr_1.3.1 kableExtra_1.4.0
#> [5] knitr_1.45 crmPack_2.0.0.9149 ggplot2_3.5.0
#>
#> loaded via a namespace (and not attached):
#> [1] gtable_0.3.4 xfun_0.43 bslib_0.7.0
#> [4] lattice_0.22-6 vctrs_0.6.5 tools_4.3.3
#> [7] generics_0.1.3 parallel_4.3.3 tibble_3.2.1
#> [10] fansi_1.0.6 highr_0.10 pkgconfig_2.0.3
#> [13] checkmate_2.3.1 desc_1.4.3 lifecycle_1.0.4
#> [16] compiler_4.3.3 farver_2.1.1 stringr_1.5.1
#> [19] textshaping_0.3.7 munsell_0.5.1 htmltools_0.5.8.1
#> [22] sass_0.4.9 yaml_2.3.8 pillar_1.9.0
#> [25] pkgdown_2.0.7 jquerylib_0.1.4 cachem_1.0.8
#> [28] parallelly_1.37.1 tidyselect_1.2.1 digest_0.6.35
#> [31] mvtnorm_1.2-4 stringi_1.8.3 purrr_1.0.2
#> [34] labeling_0.4.3 fastmap_1.1.1 grid_4.3.3
#> [37] colorspace_2.1-0 cli_3.6.2 utf8_1.2.4
#> [40] GenSA_1.1.14 withr_3.0.0 scales_1.3.0
#> [43] backports_1.4.1 rmarkdown_2.26 lambda.r_1.2.4
#> [46] gridExtra_2.3 futile.logger_1.4.3 rjags_4-15
#> [49] ragg_1.3.0 memoise_2.0.1 coda_0.19-4.1
#> [52] evaluate_0.23 viridisLite_0.4.2 rlang_1.1.3
#> [55] futile.options_1.0.1 glue_1.7.0 formatR_1.14
#> [58] xml2_1.3.6 svglite_2.1.3 rstudioapi_0.16.0
#> [61] jsonlite_1.8.8 R6_2.5.1 systemfonts_1.0.6
#> [64] fs_1.6.3